
project Reactor? 리엑티브 프로그래밍 패러다임을 구현한 스프링 프로젝트입니다.
기본적으로 OOP 에서의 Observer 디자인 패턴에서 발전한 것입니다
- Publisher
- Subscriber
Subscriber 가 Publisher 에게 subscribe 하면 Publisher 가 데이터를 push 합니다.
onNext x 0..N [onError | onComplete]
Publisher 의 push는 이러한 구조로 동작합니다. 0에서 N개의 데이터가 onNext 호출을 통해 push 되고 에러 처리는 onError 호출로, onComplete 호출함으로 종료 됩니다.
왜 이러한 비동기 라이브러리가 필요한가?
현대 어플리케이션에서는 거대한 동시접속자 수를 경험하고있고 하드웨어의 성능이 향상되고 있더라도 소프트웨어의 성능은 여전히 중요한 관심사 입니다. 프로그램의 성능을 향상시키는 방법은 많은 스레드와 많은 하드웨어 장비를 통해 병렬화를 시키거나 현재 사용중인 리소스를 효율적으로 사용하는 것입니다.
Java 일반적으로 blocking 코드 방식으로 쓰여지고 있습니다. 만약 병목현상이 일어나 문제가 발생한다면 보통 스레드를 추가해야 하는데 스레드를 추가할수록 동기화에 대한 문제가 발생하게 됩니다.
blocking 코드의 더 나쁜점은 자원을 낭비하고 있는 점 입니다. 데이터베이스 요청이나 네트워크 호출과 같은 입출력 대기 시간에 blocking 코드에서는 스레드들이 idle 상태가 되고 자원이 낭비됩니다.
- callbacks
- Futures
이러한 blocking 방식의 문제점을 해결하고자 asynchronous 방식의 모델링 방식이 callback 과 futures입니다.
이 모델링 방식또한 callback hell 이나 가독성 문제가 있습니다.
reacotr는 asynchronous의 단점을 해결하고 아래와 같은 몇가지 특징을 같고 있습니다.
- 합성성과 가독성
- 다양한
operator를 통한 데이터 변형 subscribe전에는 어떠한 동작도 하지않음Back-Pressure
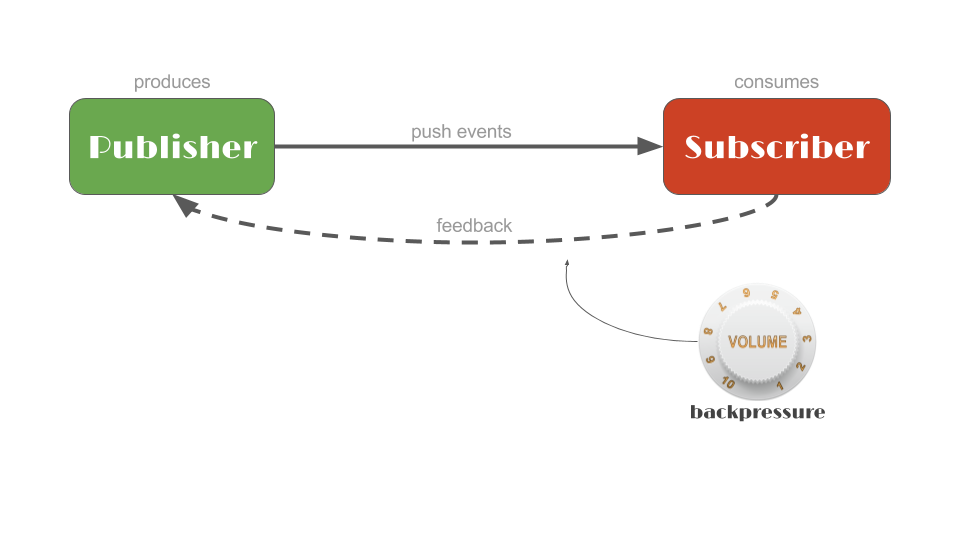
Back-Pressure에 대한 개념이 생소하였는데 Subscriber가 Publisher 가 push 해주는 데이터나 이벤트들의 흐름을 제어하는 것으로 보여집니다. 예를 들어 Subscriber 가 cancel 메소드를 호출하거나 request(Long n) method 호출을 통해 이벤트 흐름을 제어하는 것을 Back-Pressure라고 합니다.
Flux
Flux<T> 는 리엑티브 스트림에서 Publisher 입니다.
Flux 는 0 에서 n 까지의 요소를 생성한 후 onComplete onError 이벤트를 발생시킬수 있습니다.
Flux 생성 factory method
empty Flux
Flux.empty();
1개 이상의 Flux
Flux.just("1", "2");
Flux.formIterable(Arrays.asList("1", "2", "3", "4"));
Flux 에서 exception 처리
Flux.error(new Exception());
Flux infinite stream
AtomicReference<Long> l = new AtomicReference<Long>(0L);
Flux.generate((SynchronousSink<Long> sync) -> sync.next(l.getAndSet(l.get() + 1) ) );
Flux.generate(() -> 0L, (state, sink) -> {
sink.next(state++);
return sate;
})
Mono
Mono<T> 는 Publisher입니다.
create Mono
Mono.empty();
Mono.never();
Mono.just("mono");
Mono.error(new Exception());
map, flatMap 연산자는 element 를 변환시킵니다.
표현에서의 차이는
- Flux map(Function<T, U>)
- Flux
flatMap(Function<T, Publisher >) `Function<T, U>` 에서 변환 타입의 U와 Publisher 의 차이입니다.
@Test
public void flux(){
Flux<String> f1 = Flux.just("a", "b", "d", "c", "f")
.map(s -> "[" + s + "]");
Flux<String> f2 = Flux.just("a", "b", "d", "c", "f")
.flatMap(s -> Mono.just("[" + s + "]"));
f1.subscribe(System.out::println);
f2.subscribe(System.out::println);
}
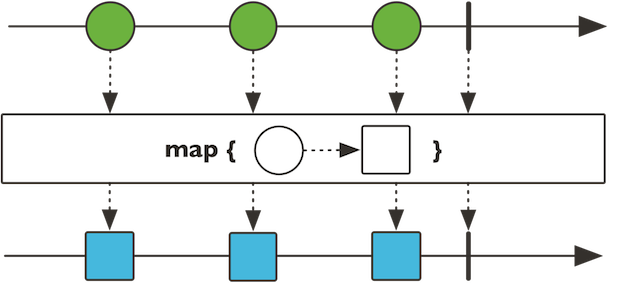
map 은 각각의 item 들이 동기적, non-blocking 방식으로 적용 됩니다.
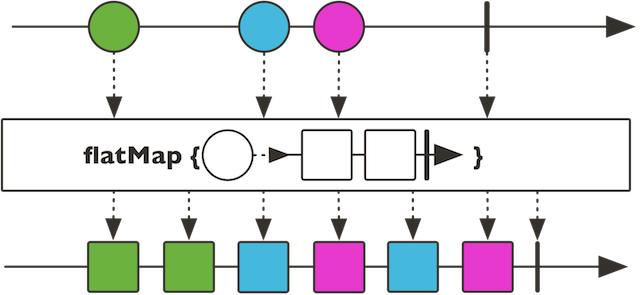
flatmap은 비동기적, non-blocking 방식으로 적용됩니다.
concat, merge
concat publisher가 complete 되기전까지 다음것을 subscribing 하지 않습니다.
![concat function(/jlog/assets/img/20180724/concat.png)
merge 는 concat과 반대로 publisher 들을 비동기적으로 다룹니다.
![concat function(/jlog/assets/img/20180724/merge.png)
@Test
public void fluxConcat() throws InterruptedException {
Flux<String> flux1 = Flux.just("[1]", "[2]", "[3]", "[4]");
Flux<String> flux2 = Flux.just("(1)", "(2)", "(3)", "(4)", "(5)");
Flux<String> intervalF1 = Flux.interval(Duration.ofMillis(500L))
.zipWith(flux1, (i, str) -> str);
Flux<String> intervalF2 = Flux.interval(Duration.ofMillis(700L))
.zipWith(flux2, (i, str) -> str);
Flux.concat(flux1, flux2)
//.log()
.subscribe(s -> System.out.print(s)); //(1)(2)(3)(4)(5)[1][2][3][4]
Thread.sleep(3 * 1000L);
System.out.println();
flux1.concatWith(flux2)
.subscribe(System.out::print); //(1)(2)(3)(4)(5)[1][2][3][4]
System.out.println();
Thread.sleep(3* 1000L);
Flux.concat(intervalF2, flux1).subscribe(System.out::print); //(1)(2)(3)(4)(5)[1][2][3][4]
System.out.println();
Thread.sleep(6* 1000L);
}
@Test
public void fluxMerge() throws InterruptedException {
Flux<String> flux1 = Flux.just("[1]", "[2]", "[3]", "[4]");
Flux<String> flux2 = Flux.just("(1)", "(2)", "(3)", "(4)", "(5)");
Flux<String> intervalF1 = Flux.interval(Duration.ofMillis(500L))
.zipWith(flux1, (i, str) -> str);
Flux<String> intervalF2 = Flux.interval(Duration.ofMillis(700L))
.zipWith(flux2, (i, str) -> str);
Flux.merge(intervalF1, intervalF2)
.subscribe(System.out::print); // [1](1)[2](2)[3][4](3)(4)
Thread.sleep(3* 1000L);
}
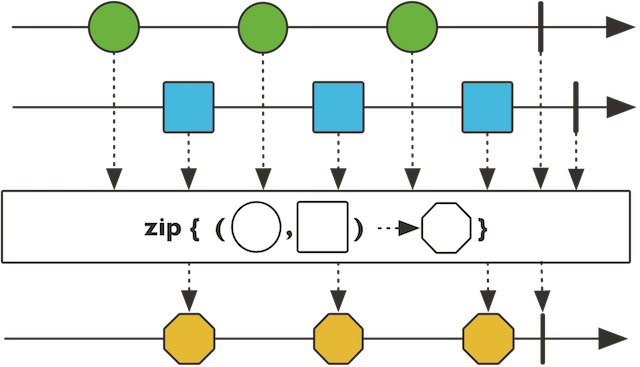
@Test
public void fluxZip() throws InterruptedException {
Flux<String> flux1 = Flux.just("[1]", "[2]", "[3]", "[4]");
Flux<String> flux2 = Flux.just("(1)", "(2)", "(3)", "(4)", "(5)");
Flux.zip(flux1, flux2, (item1, item2) -> "#" + item1 + "//" + item2 + "#")
.subscribe(System.out::print); //#[1]//(1)##[2]//(2)##[3]//(3)##[4]//(4)#
}
error
Reactor에서는 error를 처리하는 몇가지 operator가 있습니다.
- doOnError : 예외 발생시 어떤 행위를 합니다.
- onErrorReturn : 특정 값을 return 합니다.
- onErrorResume : 예외 발생시 다른 flux 로 return 합니다.
@Test
public void errorHandle(){
Flux<String> f = Flux.range(1, 4)
.map(s -> {
if (s <= 3) {
return "item : " + s;
} else {
System.out.println("<< throw RuntimeExcpetion.");
throw new RuntimeException();
}
});
f.doOnError(e -> {
e.printStackTrace();
System.out.println("doOnError : " + e);
})
.subscribe(System.out::println);
f.onErrorReturn("에러 : " + 3)
.subscribe(System.out::println);
}
정리
spring5 web-flux 를 접하며 리엑티브 프로그래밍을 처음접하게 되었고 reactor도 정리하게 되었습니다.
reactor 활용 방법이나 디버그, 테스트 방법에 대해서도 정리가 필요해보입니다.