
프로그램에서 select sql문을 빈번하게 작성해보았고, 검색 조건들에 대해서는 당연 스럽게 모두 인덱스를 추가해 사용했습니다.
rdbms에서 index 추가는 성능상의 이유로 무조건적으로 당연하다고만 여겨왔고 index 동작방식, 장단점, 효율적인 index 사용에 대한 물음에는 답을 할수가없었습니다.
rdbms 의 index에 대해서 명확하게 이해하고 몇몇 rdbms 에서의 index 사용법에 대해 정리해보겠습니다.
index?
index 개념을 책을 예로 들어 설명해 보겠습니다.

저는 마블 백과사전이라는 책을 샀습니다. 저는여기서 스파이더맨에 대한 정보만 찾아보고 싶습니다.
책의 1페이지 부터 한장, 한장씩 읽어보며 스파이더맨에 대한 정보를 검색해 봅니다. 이책은 무려 440페이지 짜리 책이고 스파이더맨에 대한 정보를 얻기 위해서는 책을 끝까지 다 읽어야할 판입니다.
결국 포기하였습니다.
 하지만 책의 뒷페이지에 보면 색인 페이지를 제공하고 있고 스파이더맨에 대한 정보만 나온 페이지들을 정리해놨습니다.
하지만 책의 뒷페이지에 보면 색인 페이지를 제공하고 있고 스파이더맨에 대한 정보만 나온 페이지들을 정리해놨습니다.
여기서 마블 백과사전은 rdb의 table 입니다. 마블 히어로 table에서 Where hero_name = 'spider man' select sql을 조회한것입니다.
첫번째로, 첫페이지 부터 읽어보며 검색하다 포기한 행위는 full table scan 입니다.
두번째로, 색인 페이지를 활용해 검색한것은 index에 hero_name column을 추가한 것 입니다.
index 는 select sql의 속도향상이 목적입니다.
마블 백과사전의 색인 페이지와 마찬가지로 rdbms 에서도 index 를 추가하게되면 파일로 저장관리하며 별도의 공간을 차지하게 됩니다. 이 index 파일을 사용하여 select 속도를 향상시키는 것 입니다.
mysql index 생성, 삭제
mysql 의 db engine에 따라 index 관리 방식이 다릅니다.
- MyIsam
- .frm : 테이블 정의 파일
- .MYD : 테이블 데이터 파일
- .MYI : 테이블 인덱스 파일
- tablespace 에서 관리
index 생성 (column 명은 1개부터 n개 까지 가능합니다.)
ALTER TABLE tbl_marvel_hero ADD INDEX idx_marvel_hero (hero_name, hero_age);
CREATE INDEX idx_marvel_heor ON tbl_marvel_hero(hero_name(10));
index 삭제
ALTER TABLE tbl_marvel_hero DROP INDEX idx_marvel_hero;
postgresql index 생성, 삭제
생성한 index 는 base directory 밑에서 파일로 관리 됩니다.
single or multi index 생성
CREATE INDEX idx_marvel_hero ON tbl_marvel_hero USING btree(hero_name, hero_age);
unique index 생성
CREATE UNIQUE INDEX idx_marvel_hero ON table_name(hero_code);
clusterd index 생성
ALTER TABLE tbl_marvel_hero CLUSTER ON idx_marvel_hero;
index 삭제
drop index idx_marve_hero;
index 종류
B-Tree index
B-Tree index는 인덱싱 알고리즘에서 가장 일반적인 사용방법입니다.
B 는 “Balanced”를 의미합니다.
B-Tree 자료구조에 대해서 짚고 넘어가 보겠습니다.
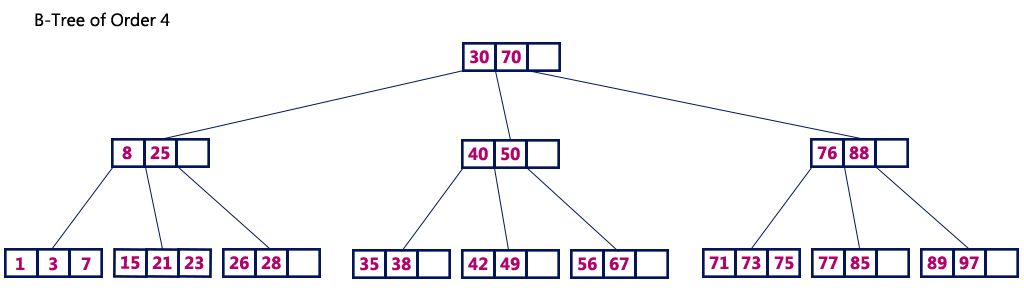
- B-Tree 는 하나의 노드에 여러자료가 배치되는 트리구조 입니다.
- 노드에 최대 배치 가능한 자료수에 따라 m 차 B-Tree 라고 부릅니다.
- 자식의 수 = 노드의 자료수 + 1
- “Root” 는 2개이상의 자식을 가집니다.
rdbms 인덱싱 B-Tree 구조 입니다.
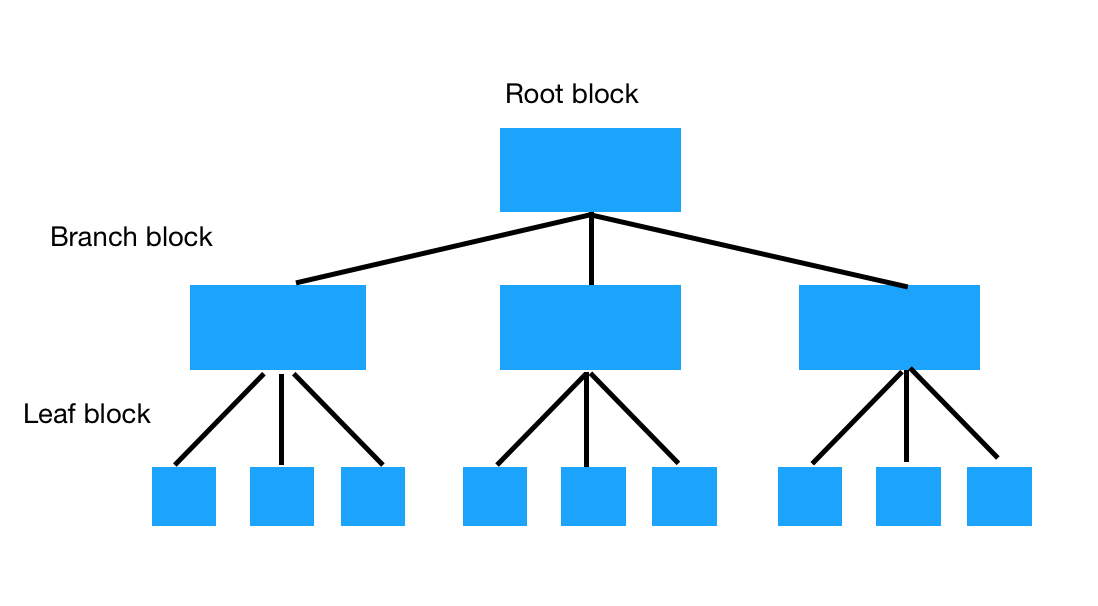
B-Tree index 는 root block, branch block, leaf block으로 구분 하게 됩니다.
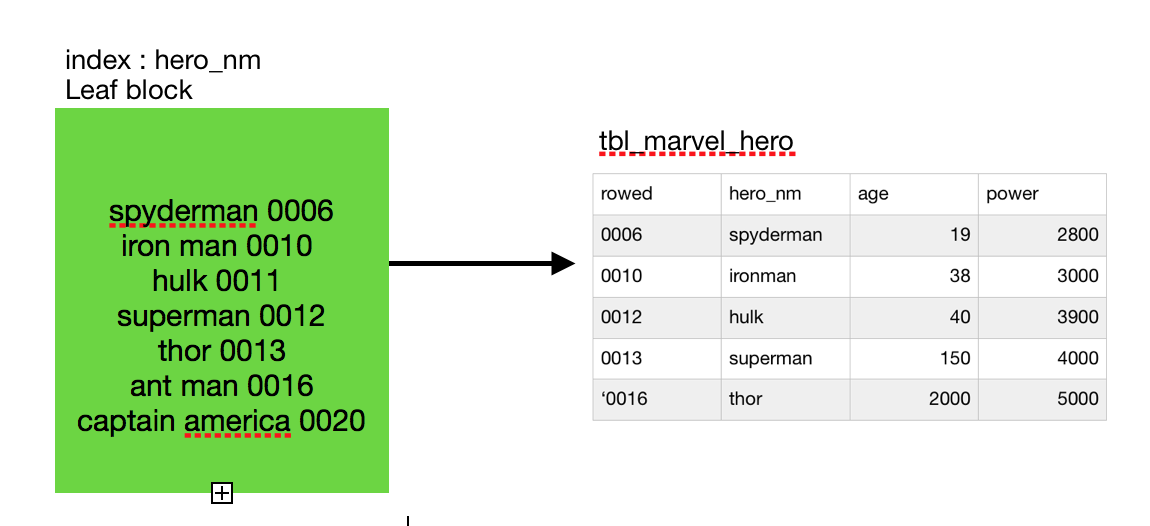
leaf block 에 index data와 rowid정보가 존재합니다.
실제로 rowid 정보는
- Data Object : database SEGMENT식별 정보
- Relative File : tablespace datafile 번호
- Block : data block 번호
- row number : row slot 번호
4가지 정보를 갖고있습니다.
인덱스 별로 이러한 B-Tree 구조를 갖고 있기 때문에 insert, update, delete sql 실행시에는 B-Tree 에서는 insert, delete 시에는 index data 를 삭제하지 않고 사용하지 않는 표시를 합니다.
index scan
Range Scan
인덱스의 root block 에서 수직적으로 탐색한 후 leaf block에서 필요한 범위만을 스캔하는 방식입니다.
인덱스를 구성하는 선두 컬럼이 조건절에 사용되어야 index ragne scan이 가능합니다.
Full Scan
수평적으로 leaf block 을 탐색하는 방식입니다.
인덱스의 선두 컬럼이 조건절에 없을때 주로 수행합니다.(Table Full Scan 보다 I/O 를 줄이거나 정렬된 결과를 쉽게 얻을 수 있을때)
index 조건시 고려사항
아래의 조건들은 인덱스 범위에 대한 결정조건으로 사용할 수 없습니다.
- not eaqual 비교
where column <> 'N'; where column NOT IN(1,2,3); where column is NOT NULL - LIKE 뒷부분 비교
where column LIKE '%man'; where column LIKE '%man%'; - stored 함수나 다른 연산자로 인덱스 컬럼 변형
where SUBSTRING(column) = 'change'; where DAYOFMONTH(column) = 1; - 다른 데이터 타입의 비교
where char_column = 10; - 문자열 데이터 타입 콜레이션이 다른경우
where utf8_bin_char_column = euckr_bin_char_column; - 컬럼값 변형
where column * 2 > 200; -- 아래와 같이 사용 where column > 200 / 2;
인덱스 컬럼의 선정으로 고려할 사항들입니다.
- 분포도가 좋은 컬럼
- 분포도가 좋은 컬럼은 인덱스를 단독적으로 생성하여 활용도를 향상
- 수정이 빈번하지 않는 컬럼 (DML 작업)
- 한 컬럼이 여러 인덱스에 포함되지 않도록 고려
- 기본키 및 외부키가 되는 컬럼
- 결합 인덱스의 첫번째 컬럼순서 선정에 주의
정리
그동안 깊게 생각해 본적이 없었는데 구체적인 index 의 동작을 살펴보며 sql문을 작성할때 여러 고려해볼 점이 생겼습니다.
가장 기본적인 B-Tree 방식 기준으로 알아보았는데 이외에도 B+-Tree 같은 다양한 자료구조를 사용하는 방식이 많습니다.
또한 각 dbms별로(mysql, postgresql) index 활용방법에 대해서 추가로 포스팅이 필요해 보입니다.
출처
- https://m.blog.naver.com/PostView.nhn?blogId=seongjini&logNo=220704178273&categoryNo=7&proxyReferer=https%3A%2F%2Fwww.google.co.kr%2F
- http://12bme.tistory.com/138
- http://btechsmartclass.com/DS/U5_T3.html
- http://wiki.gurubee.net/pages/viewpage.action?pageId=4949506
- http://www.gurubee.net/lecture/1107